There are quite a few new features in Oracle BPEL 12c and here is one that I really like; the BPEL subprocess – a task/algorithm that is an association (not composition) of an activity/process.
The concept has been around for decades and it has featured in process diagrams and BPMN notation for quite a while, but there was no equivalent in program code. Oracle has finally addressed this lacuna by releasing a feature in BPEL that closely approximates the design concept. Please note that it is close but not identical in semantics; but that again is to be pedantic – pardon the pun!
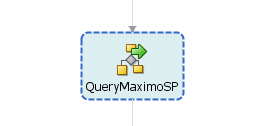
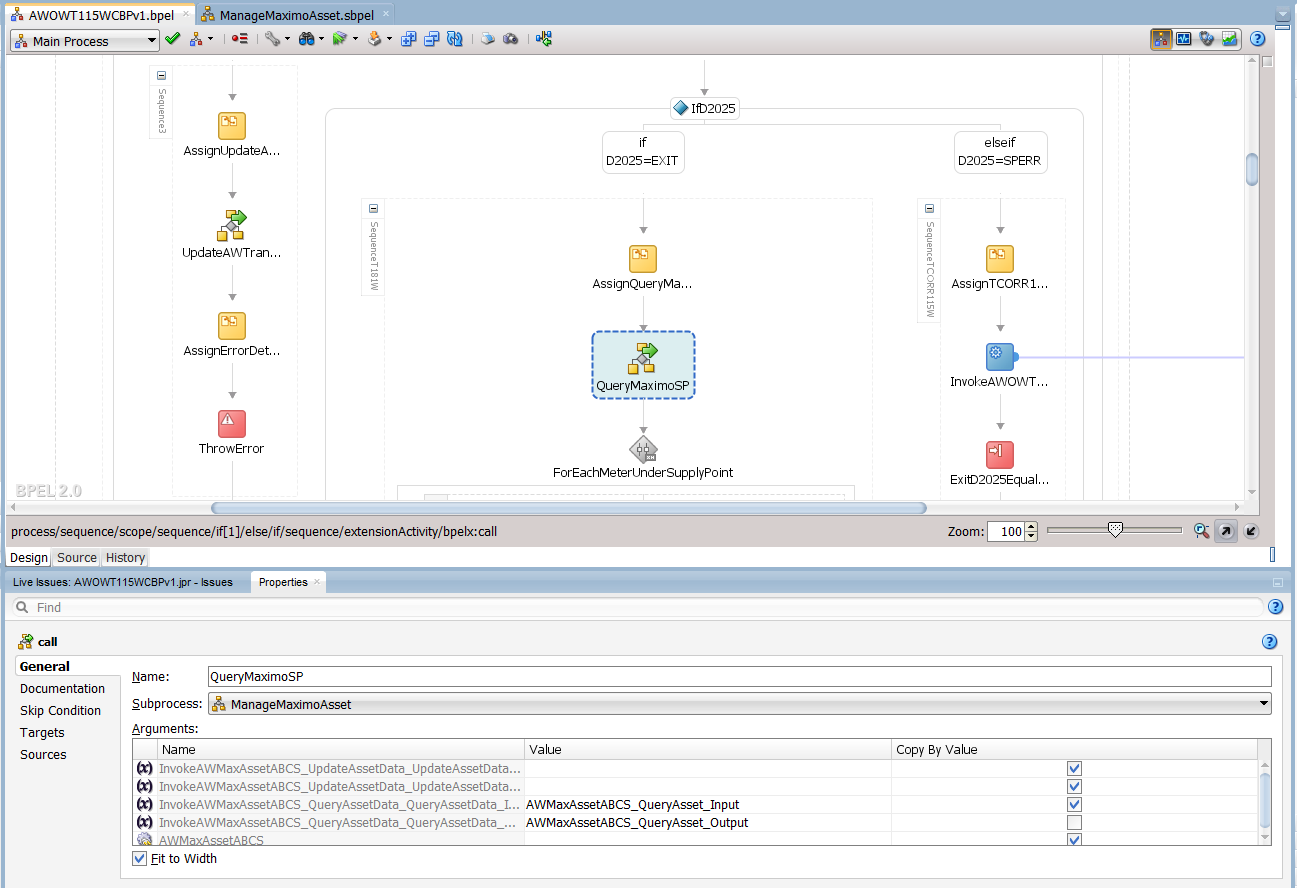
The subprocess allows a programmer to define a block of code or algorithm that will be reused as-is at various points within one or more BPEL processes. I took the liberty of taking a few screenshots of active code from a recent client in order to illustrate a subprocess in action. Before diving in though, it is useful to set the context. The subprocess is being used in this scenario to wrap the invocation of operations on a service, and the task is named here as “QueryMaximoSP” – see highlighted item in the diagram below.
Call to the subprocess from the parent process
 |
 |
 |
This subprocess wraps all the operations on the AWMaxAssetABCS service, and can determine which one is to be invoked by examining the inputs it receives from a main process. In this simple example, the choice is implemented as if/else paths for “query” and “update” operations. Once the operation has been determined invocation of the target service follows, using the input that was passed in by the main process.
Subprocess internal details
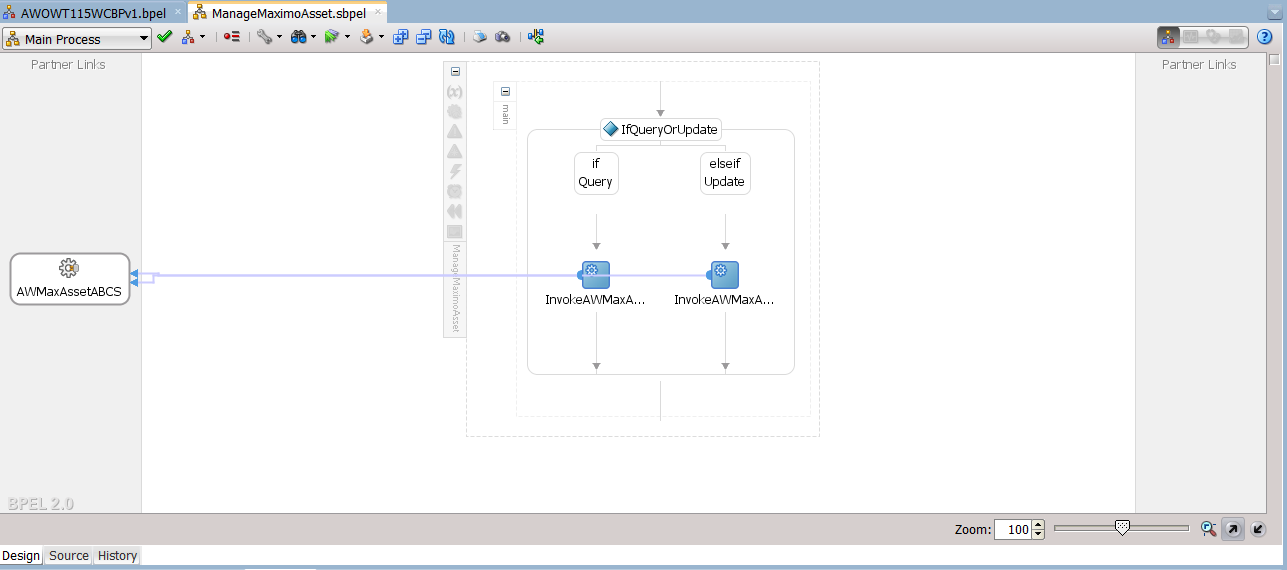 |
There are three benefits that this concept brings to BPEL code:
- Simplification of design view
- Improved reusability
- Improved modularisation
In the design view, hiving off some code into a subprocess frees up the screen from clutter and makes it much easier to see the big picture of what we are doing in the main process. But what becomes of all this delegated code in production systems? One fear may be that the subprocess will be displayed as a black-box. This is not the case, all steps in the subprocess will be revealed at runtime, but only if they are executed.
Modularisation is improved because programmers can delegate as much logic to the subprocess as needed, including specialised error-handling and rollback, pre/post processing, and other conditional processing. All of this functionality is thereafter available to all processes within a SOA composite, and each can invoke (reuse) the same subprocess multiple times with different inputs.
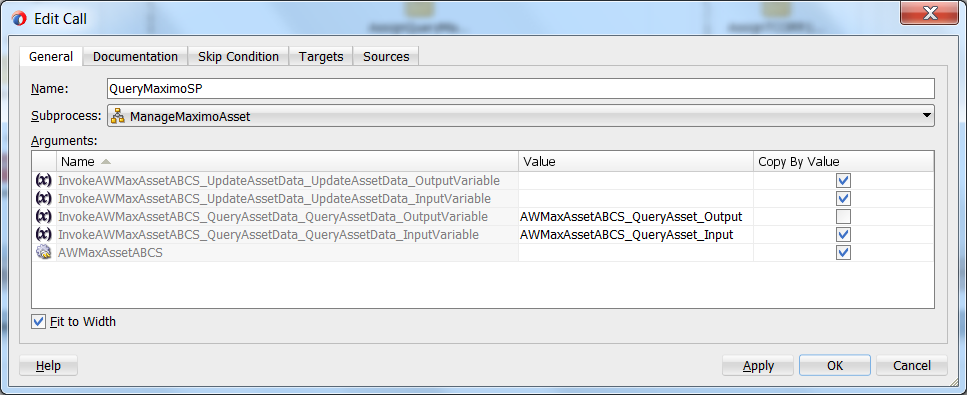
In the diagram below, input has been provided for the query operation while the update operation has been left blank, and so only the query operation will be acted upon in the subprocess. Notice also that the “Copy By Value” checkbox of the output variable has been left unchecked. This is important, as the invocation is likely to fail on the output variable if the checkbox is checked.
I have found it really useful to encapsulate the invocations to partner services in subprocesses, so that I can control all necessary pre and post processing in one place, as well as any necessary error handling and recovery that is specific to that partner system. In future, it would be nice to have subprocesses that more closely resemble the concept in process models, i.e. a unit of functionality that can be reused across the domain, not just within one composite. Now, some would argue that we should create a new composite to encapsulate the required functionality, but of course that would not be the same thing as in the model, and such a construct would also be significantly slower, not to mention that it would not fit nicely into a service portfolio. Let’s wait and see if Oracle will be tweaking this feature in the next release of the JDeveloper and SOA Suite; for now though, there are already some great benefits realised in subprocesses. I hope you find it useful too.
Regards and God bless.
—
Oyewole, Olanrewaju J (Mr.)
Internet Technologies Ltd.
lanre@net-technologies.com
www.net-technologies.com
Mobile: +44 [0] 793 920 3120