
![[Hybrid] Cloud Infrastructure](https://blog.net-technologies.com/wp-content/uploads/2017/12/ExeterUni_CloudInfrastructure.03.png)
Cloud and Open Source
The arrival of Cloud providers and Infrastructure-as-a-Service (IaaS) has opened up options and possibilities for solution architects. Our company is working with a client on a major transformation initiative. Leveraging Cloud IaaS and open-source integration platforms, together we have explored options, built competence, and delivered incremental solutions while keeping costs to a minimum. Without Cloud IaaS and open-source this freedom of expression in solution architecture would have been impossible. Just imagine justifying a multi-tier, multi-server solution to the CFO when one of the key drivers has been cost control!
The Basic Idea
In its most primitive expression, our client wanted a public Application Program Interface (API) layer to abstract access to an Integration layer, which in turn connected with all their internal repositories and partner systems to provide services. The image that follows provides an illustration. It appears quite straightforward and simple.
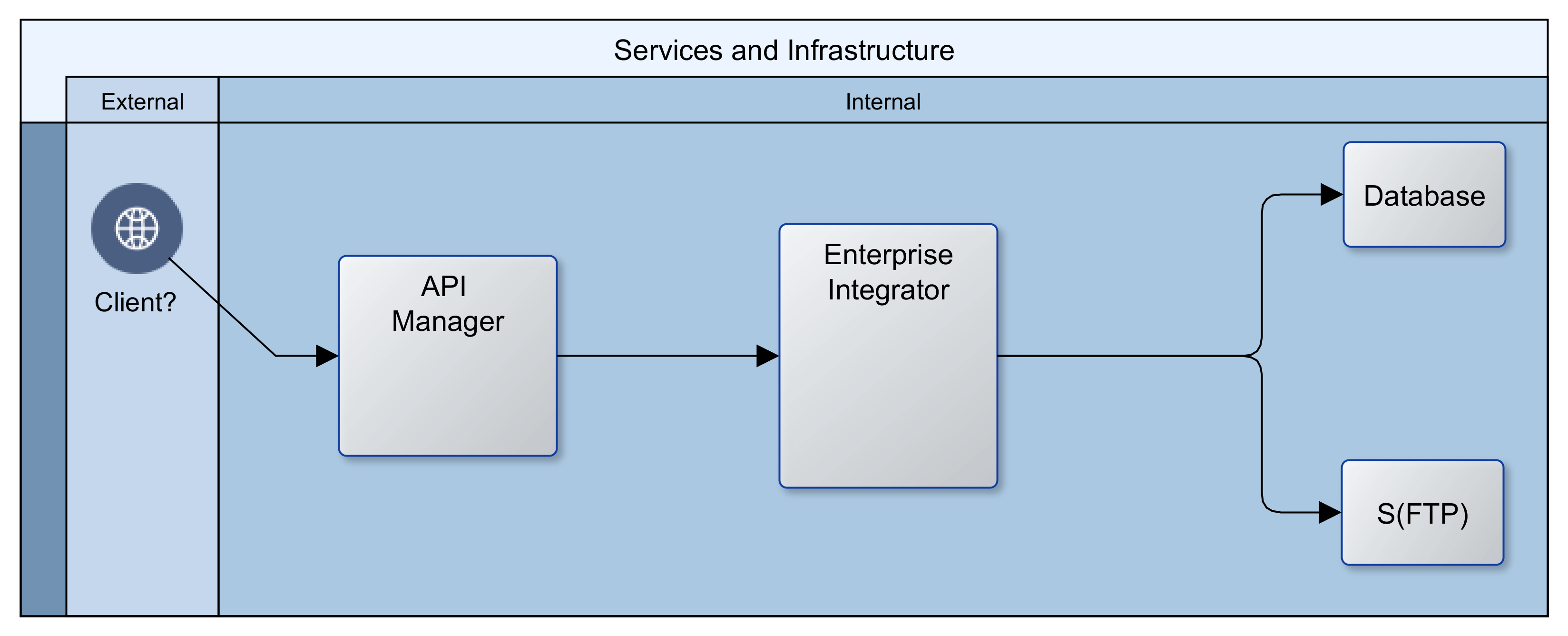
The API layer provides a simple Representation State Transfer (REST) interface as well as security. It also maintains logs that can be analysed for insights into client behaviour and the usage/performance of services. The Integration layer serves as an Enterprise Service Bus (ESB), connecting to databases, FTP and/or file servers, as well as internal and partner web services. In addition, it manages the interactions between all participating systems in the enterprise and ensures that valuable services are made available to the API layer.
Enter Cloud (AWS/Azure) and Open Source (WSO2)
The traditional route would have been to procure/secure access to servers in a data-centre or in-house server-room and buy licenses from a vendor. That would have meant a lead time of several weeks or months, to negotiate the price of licenses and consultancy, arrange for servers and networking, and to secure and disburse requisite financing. With Cloud and open-source software, upfront costs were near-zero. The greatest resource demand was the effort required to architect the Cloud infrastructure and to create the code to build, populate and operate it.
Building the Foundation
There were many options for building the networking and computing instances. We chose Kubernetes. Kubernetes is well established and provides abstractions that make it easy to switch Cloud providers. Using the analogy of a house for illustration; Kubernetes builds the shell of the house, setting up the rooms, corridors, and spaces for windows and doors. It keeps a record of each component, and notifies all other components if there has been a change to any one of them. In our use case, Kubernetes creates a private network in the Cloud (cluster), adds compute-instances, load-balancers, firewalls, subnets, DHCP servers, DNS servers, etc. Kubernetes also provides a dynamic registry of all these components that is kept up to date with any changes in real time.
The First Change: Redundancy
In the past, vertical scaling with large singleton servers was standard. These days, horizontal scaling with smaller machines (compute instances) that adjust to changing needs is the norm. This new approach also provides fail safety. If one machine fails, there will be other(s) to take up the load. Fortunately this is a core feature of Kubernetes. The cluster monitors itself to ensure that all the declared components are kept alive. If/when a component fails, the management services within the cluster ensure that it is replaced with an identical component. For this reason, rather than have one instance of each component, two or more are created and maintained.
The Second Change: Dynamic Delivery
We could have chosen to install all of our technology stack (software) on each compute instance on creation. That would be slow though, and it could mean that the instances would need to be restarted or swapped-out more often as memory and/or disk performance degrade. Instead of that, we used Docker to build Containers that are delivered to the instances. The Docker Containers borrow memory, CPU and other resources from the compute instance at the point of deployment. Containers can be swapped in and out, and multiple Containers can be run on the same compute instance. When a Container is stopped or removed, the block of borrowed resources are returned to the compute instance. A Container can be likened to a prefabricated bathroom; it is built offsite and plumbed in at delivery. Unlike a technology stack that is built from scratch over minutes or hours, a Container is usually ready for access within a few seconds/minutes of its deployment.
Implicit Change: Clustering
When more than one instance of a genre component is running at the same time, the complement of all is referred to as a cluster. Components running in a cluster have peculiar needs; one of which is the sharing of state (status). State is a snapshot of the world from the computer’s perspective. In a cluster, all component instances must share the same configuration and operate on the same data always. To facilitate this, we introduced two repositories. A Network File System (NFS) for sharing configuration details, and a database for sharing operational data. Kubernetes does not create these resources. We used Terraform, another abstraction technology, to create the NFS and a replicated multi-zone database. Terraform creates these in two private subnets within the private network created by Kubernetes. Having created the NFS and database though, there was a need to configure and populate them with necessary data upfront. While Terraform could be manhandled to achieve this, it is not really it’s raison detre. Another tool is more suited to operating at a fine detail on remote machines: Ansible. We created Ansible playbooks to configure users, directories and files on the NFS and to create instances, users and tables in the database.
Implicit Change: Discovery
The next challenge that our architecture threw up was discovery. Within our network, there was an API layer and an EI layer. In each of these layers, there could be several compute instances, and on each compute instance there could be one or more Docker Containers. Beyond the API and the EI layers, there were also databases and a network file system. How would clients or our platform gain access to our components, and how would the machines in one layer find those in another layer? The Kubernetes configuration includes ClusterIP services that provide a single DNS name that resolves to all the compute instances for a given component. For example, any API Container could be reached using a DNS name such as: cnt.api.example.com. Clients of our platform could therefore use a DNS name to connect to an API Container, and any API Container could likewise use a single DNS name to communicate with a Docker Container in the EI layer. Both the API and EI layers use a DNS name to communicate with the NFS and the database. The IP address of the underlying components might change, but the DNS name is constant for the life of the platform, giving ease of discovery and stability.
Tying it all Up
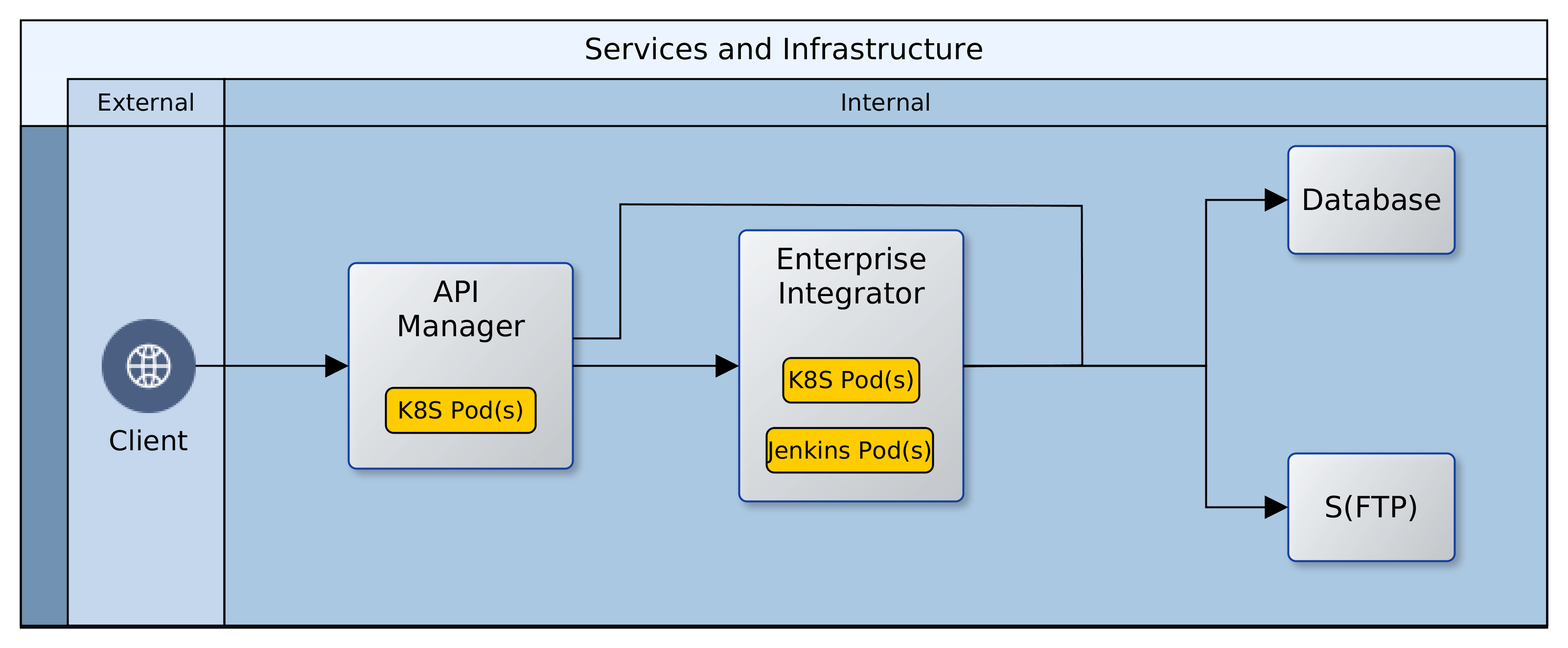
It is all well and good that the components in the Cloud are in place and can talk with each other. However, most of our operational systems are still on-premise; how do we join things up? We created a VPN connection between the network in the Cloud and our on-premise network and set up Firewall rules to allow access to and from the Cloud. The ClusterIP services were also revised to permanently maintain two static IP addresses. This makes it easy to integrate them with on-premise DNS servers and thereby open them up to access from clients. Below is an image that shows what it all looks like.
![[Hybrid] Cloud Infrastructure](http://blog.net-technologies.com/wp-content/uploads/2017/12/ExeterUni_CloudInfrastructure.03.png)
The Thousand Servers
All of these components, configurations, and customisations have been documented as scripts, configuration files and resources. The creation of a Cloud environment is reduced to running a script with two parameters: the name of the environment and the desired Cloud subnet. By integrating this script into an on-premise CI/CD server, it is now possible to spin up as many Cloud environments as we like; at the click of a button.
All this is quite high-level and simplified; in the next instalment (One Thousand Servers: Start with a Script), I intend to drop down to eye-level and throw up some of the details of how we implemented all of this. Watch this space for the activation of link above.
—
Oyewole, Olanrewaju J (Mr.)
Internet Technologies Ltd.
lanre@net-technologies.com
www.net-technologies.com
Mobile: +44 793 920 3120
The Cloud is a game-changer!