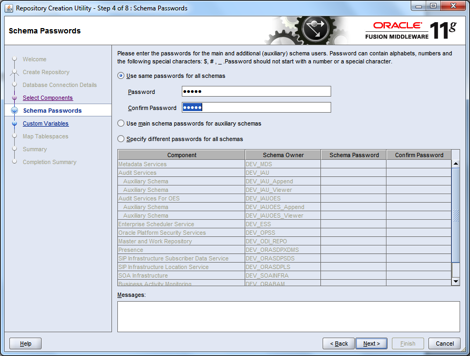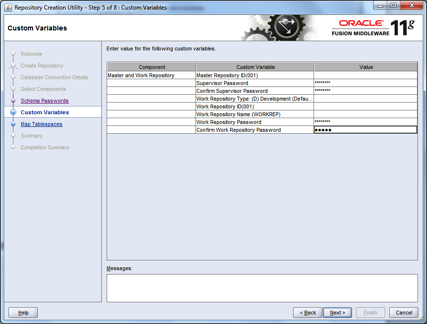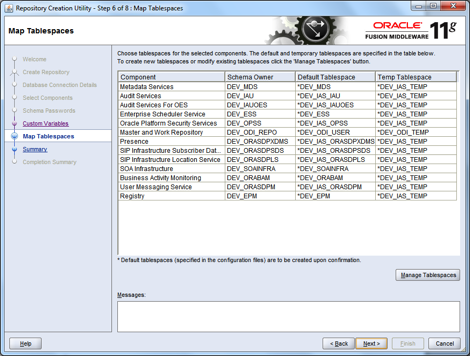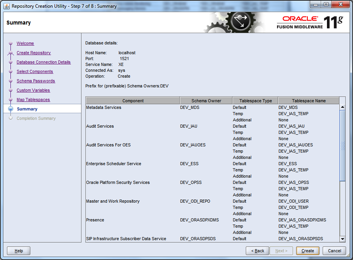
In a previous article (Custom XSD Schema…) I examined the options open to the information architect when deciding on the adoption of XSD schema for SOA service messaging, and whether to choose an industry/community standard or go for a bespoke design that is tailored for the organisation at the point in time.
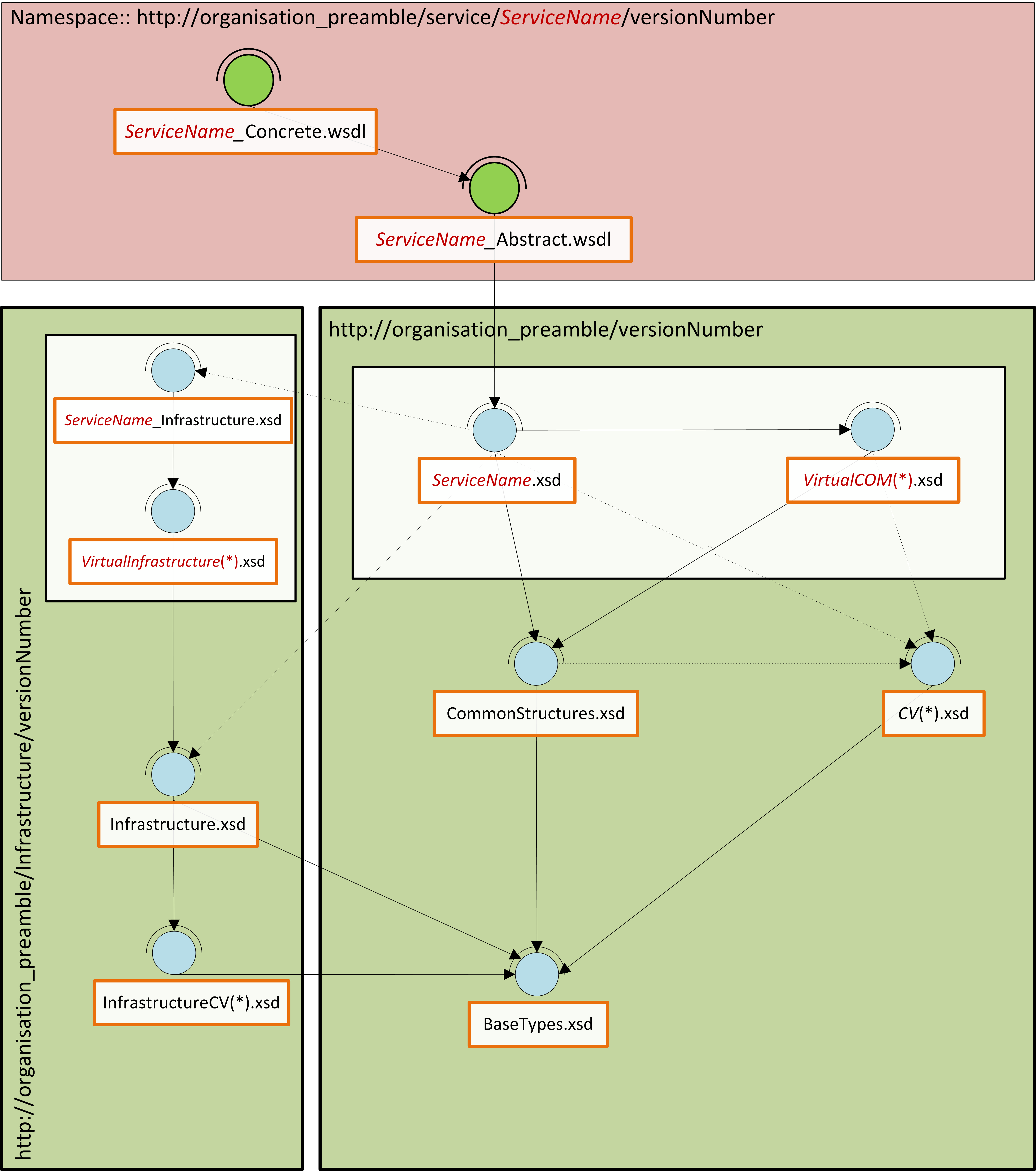
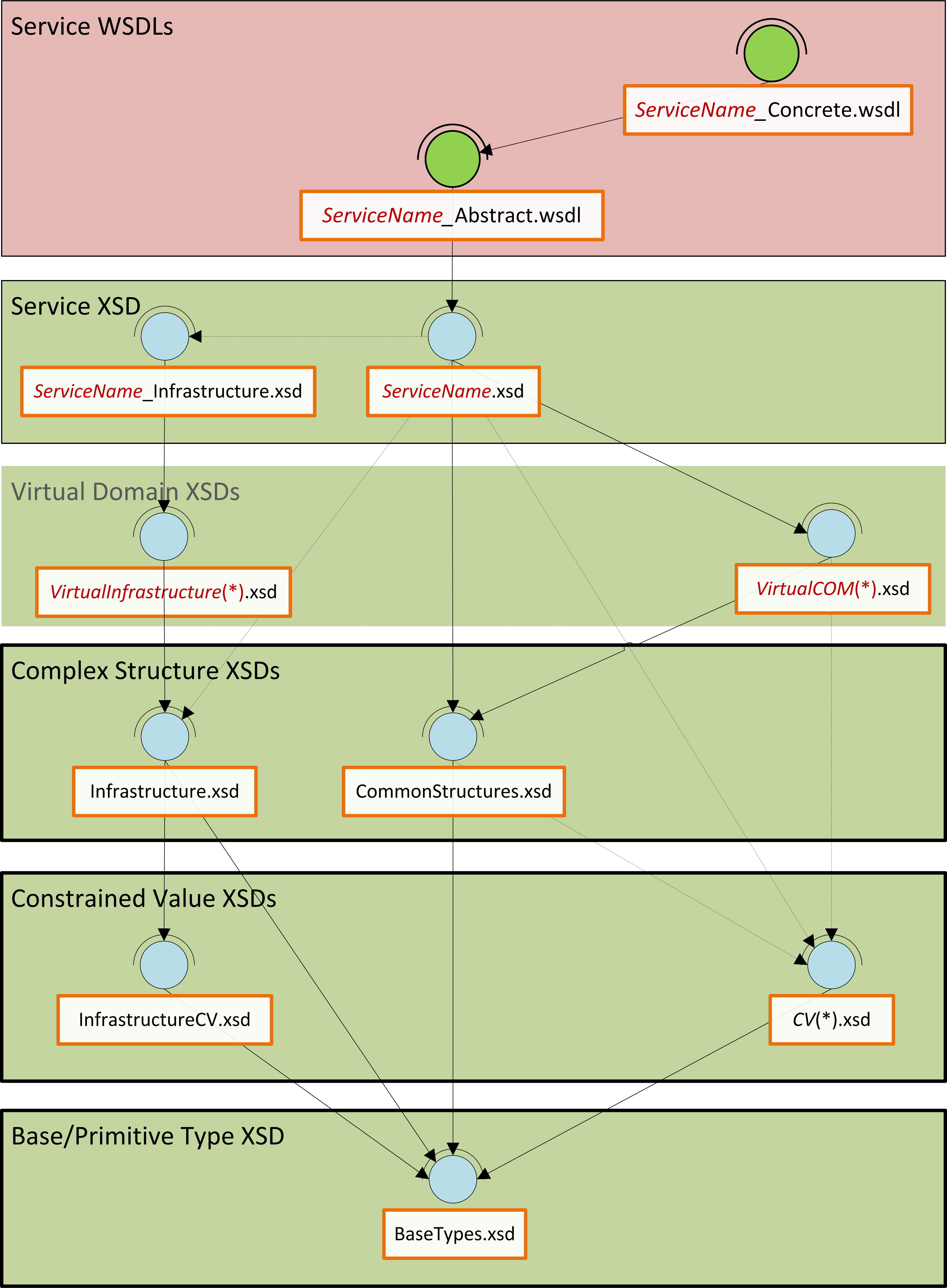
In this article, I present an overview of a custom messaging model (WSDL and XSD) that should work well for many small to medium sized IS/IT departments (10-200), especially where the information architecture function is either small or non-existent. This model is therefore more than the canonical schema, but the minimal overhead in WSDL is necessary to create an end-to-end view of the service contract that is properly aligned. So, to cut to the chase; let us start with an overview of the message model in the form of a diagram:

This message model is like one of those nice layered cakes that you get at birthday parties, each layer has a different flavour and character, and the higher layers sit on, and depend on the lower layers. Similarly, this model is built bottom up; each layer has a purpose and flavour that the layers above it depend/build on.
The Proper Canon: Base, CV and Complex:
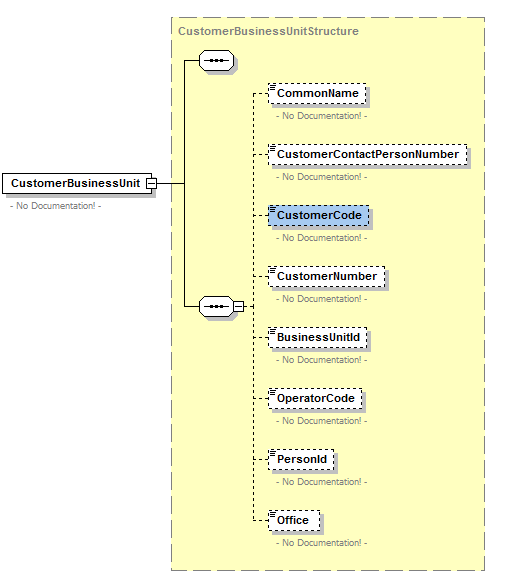
At the lowest level, there are base types that constrain required XSD primitives into a few logical and physical domains. The next layer contains the constrained value lists (enumerations), which are all constrained to one of the physical domains in the base types, and from that, define permissible values for certain static values for a generic type.
This layer introduces a peculiarity; “Infrastructure…”. This construct is adopted for one purpose, to distinguish all non-business concepts. In all the subsequent layers, any unit with “Infrastructure” in its name is concerned with IS/IT concepts rather than the core business. Above the constrained values are the complex structures: these are common compound nodes with one or more child nodes/elements. These three layers form our proper canonical schema, in that, everything in these three layers will be used as-is by all services in the enterprise. Above this layer, we encounter a virtual layer, and then a service layer, and in these and other layers, perspective is everything; there is no single view of the world!
The Virtual Domains:
This is the virtual canonical schema. The layer defines the template, or canonical form of all business and non-business (Infrastructure) concepts; the focus of this layer is coverage and correctness of definition and description rather than implementation, and this could be the bridge to an information model at some time. Peculiar to this layer is the absence of constraints on the cardinality of data items; this is deliberate. The absence of cardinality constraints makes it possible to defer this till later when development is imminent and allow all SOA services the liberty to define how the data will be used in their context. The only proviso being that the structure and relationships of the data may not be augmented in any way, i.e. no moving, renaming, adding of nodes or relationships.
The Service Schema:
This layer becomes pertinent when implementation is about to begin; and the focus is in customising data structures from the virtual canon for specific use in the request and response of operations of services that use XML. Much like the CV, Complex, Service, and Virtual layers, the service layer has business and “Infrastructure” units, but both have exactly the same function: to customise data from the virtual canon. The service schema however needs to import the service infrastructure schema, since it is assumed that most services will be business focused rather than IS/IT focused, but the relationship could also be inverted in some scenarios. For example, the data needed for CRUD (Create, Read, Update, Delete) operations will be different, and so it is useful that the interface of the Read operation is not cluttered with data that is only relevant for the Create operation. The service schema could therefore specify only the ID of an Address for the input to the Read operation, whereas the Create will certainly not have an ID, but would need almost everything else: HouseName, HouseNumber, StreetName, PostCode, etc.
Service WSDLs:
The icing is put on the cake by the way of the service WSDLs (abstract and concrete). This layer is included in the model to illustrate patterns that can be used to connect the data for the operations in the XSD to the operation definitions in the WSDL, and to support the premise that automation is not only plausible, but that auto-generation of service interfaces is on the radar. For clarification; the abstract WSDL imports the service schema and is concerned only with the data structures that are needed by a service; the concrete WSDL on the other hand defines the implementation details of the service, i.e. what structures are needed for clients to access the service at runtime.
I hope this first piece has been useful; in the next installment I will build on this by introducing a new layer that will build on this foundation: Namespaces.
Ad Majorem Dei Gloriam.
—
Oyewole, Olanrewaju J (Mr.)
Internet Technologies Ltd.
lanre@net-technologies.com
www.net-technologies.com
Mobile: +44 [0] 793 920 3120