Like most folks on the planet right now, AIs have been one of my major areas of interest and attention; at least in the last two years. Yes, I caught on late. But it was not for want of trying. It was just that the first wave of AIs, were too low-level for me. The theoretical aspects of the courses run by Google and the University of Helsinki were accessible to me, but the maths blew me away completely. Now I wished I had paid more attention in maths class 🙂
Well, all is not lost, and as often happens in IT, the second wave, or should I say evolutionary kind of the technology abstracts away much of the complexity of the earlier kind. Yes, you lose access to a lot of the fine-grained controls, but hey, how many folks care about the difference between Transformers and the CNNs and RNN, or what about the algorithms used by AMAs for prompt reliability? Or this simple equation from LLM calibration q^=Softmax(Wp^+b)?
Have a good look at the headline image. Those three amigos are your friends in the world of AIs and human interfaces to that complex nether world. I program in quite a few languages, including Python, on the side, but I never quite paid attention to it until recently. If you want to work with AIs, Python is your easy way in. The ecosystem is extensive and with several layers of abstraction that make it easy for almost anyone to enter at a level that is comfortable and accessible.
The other two are Swiss-army knives in their own right. I will not waste time describing them, as you will find a plethora of material on them on the Internet. Suffice to say that LlamaIndex allows you to easily collect data (documents, APIs, SQL, etc.) and build an index. It relies on LangChain for the indexing. LangChain is like a workflow engine and connector that provides easy interfaces (facades) to the LLMs and other tools. Both are available as libraries in Python.
A big shout-out to Wenqi Glantz for an excellent intro that I was able to implement within a few minutes. I intend to modularise your solution by separating the indexing function and making it an event-driven daemon, since the Gradio interface only needs to know where the index is and not create it each time. Gradio is another Python library that makes it easy to create a web UI, in this case, for building a chatbot. Thanks also for Confluence example, it should be adaptable for JIRA as well; both of those have rather poor search/introspection facilities.
Honestly, we are at the point now where most folks, in the tech sector at least, should be able to understand and use AIs. The Python programming language is a great place to start, and though I have mentioned only three libraries today, there are several others out there, each providing simple interfaces to advanced capabilities. Now is a great time to get into AIs. The technology has moved on from white-coats and geeks. You still get to see and understand some of the fundamentals, before it is all hidden away in later generation services and solutions. Take the plunge; I am sure you will enjoy the journey, and there is so much to learn and explore!
In chapter six of Lewis Carroll’s “Alice’s Adventures in Wonderland,” under a section, titled “Pig and Pepper.”, the following dialogue plays out:
Alice:Would you tell me, please, which way I ought to go from here? The Cheshire Cat:That depends a good deal on where you want to get to. Alice:I don’t much care where. The Cheshire Cat:Then it doesn’t matter which way you go.
There is a lesson here for interacting with emerging machine interfaces of Large Language Models (LLM) and Generative Artificial Intelligence (Gen-AI) like ChatGPT. The way we interact with computers has evolved dramatically in the last decade, to the point where one can begin to conceive of Alice’s conversation with the Cheshire cat. However, much as it was with the Cheshire cat, you still need to know where you want to go in order to benefit from directions.
Let’s imagine that you are looking for information about the topography of Berlin, Germany, and not the whole of Europe. Well, it helps to know that your target lies somewhere between Russia, the North Sea, the Mediterranean and Lebanon (context), since there is another Berlin in Ohio (US). It is useful to understand that the focus is geographical rather than political (role), that the message is in a form suited for delivery at the UN rather than the Republican conference (tone), and the format is as a speech rather than a manifesto (format). These foundations are effective for all ChatGPT interactions, whether you’re an IT architect navigating complex technical issues or a C-Suite executive seeking strategic insights.
There are many comprehensive blogs, articles, books and other materials you can read about writing effective prompts. I find that many are quite technical, and they cover details and scenarios that most folks will never need, in work, or everyday life. What I have done is to simplify things and give you the bare essentials. A simple formula that gives you the maximum revenue-to-investment ratio. The acronym CRAFT spells out: Context, Role, Action/question, Format and Tone. These are the fundamental components of every ChatGPT prompt. By applying these to your prompts, you will get much better results, and useful feedback for improving future prompts.
Context
Context is the backstory to your dialogue; it gives depth to your prompt. It provides the AI with the necessary background information to better understand your query fully. For example, if your question is about technology threats and trends, the prompt could start like this: “In the rapidly evolving tech industry, where startups are disrupting traditional players…”
Role
Here is the best way to think of the role. Think; in real life, who would I prefer to answer this question: a lawyer, plumber, dietician, legislator, soldier? The role instructs the machine on the overall nature and perspective of the response, including any inherent biases. For instance, if you’re a COO architect seeking technical insight, your prompt, continuing from the Context example above, might be of the form: “you are an experienced Cloud infrastructure expert, with several certifications and hands-on experience of Azure …”.
Action/Question
Instructions in a ChatGPT prompt are the most important component. They need to be clear, concise, and unambiguous. Brevity might be an asset here, the clearer your instructions, the more accurate and relevant the AI’s response. A compatible question to the example given in the Context could be: “what are the emerging cybersecurity threats for Azure IaaS in 2023?”
Format
This determines the presentation of the output/response of ChatGPT. It could be a detailed analysis, a concise summary, a table, bullet points, a step-by-step guide, or a combination of things? Use simple language to tell the AI how to deliver the information in a way that suits your purposes. Once again, using our example from the Context, the format could be: “a short summary with bullet points of the 5 most significant concerns”.
Tone
The tone of your prompt sets the mood for the conversation. If you were to advise the role how best to engage with the target audience; would it be technical, formal, humorous, conversational, expert, witness, informative, urgent, casual, professional, legalistic, etc. It could also be a combination, for example professional+humorous. Extending our Context example, the tone could be: “speaking with an informative tone”, since the COO does not intend to mask their unfamiliarity with the subject.
Extra Tips
Use simple and precise language; imagine that you are conversing with a 10-year-old Einstein.
Evolve the prompt, changing the keywords you use for tone and format, in order to get an output that suits your purpose.
Always leave the action/question till last, as it can help reduce verbosity and improve accuracy of the output.
Conclusion and Credits
In the ever-evolving landscape of AI, mastering the art of ChatGPT prompting is a skill that can elevate your interactions with technology. IT architects can it to seek solutions to complex technical challenges, while C-Suite executives can extract strategic insights for decision-making. From general technical information to specific market analysis and research, the applications are limitless. I am convinced that we are entering a new age of man-machine relationship, and those that learn and adapt will reap significant benefits in the future.
PS: I used an approach called “Generative Knowledge” to elicit an outline and the initial draft for this article. I had to refine the prompt a few times to get things right. The final LLM output benefited from some massaging, but all-in, it saved me a lot of time, and I hope that I managed to impart some useful information to you.
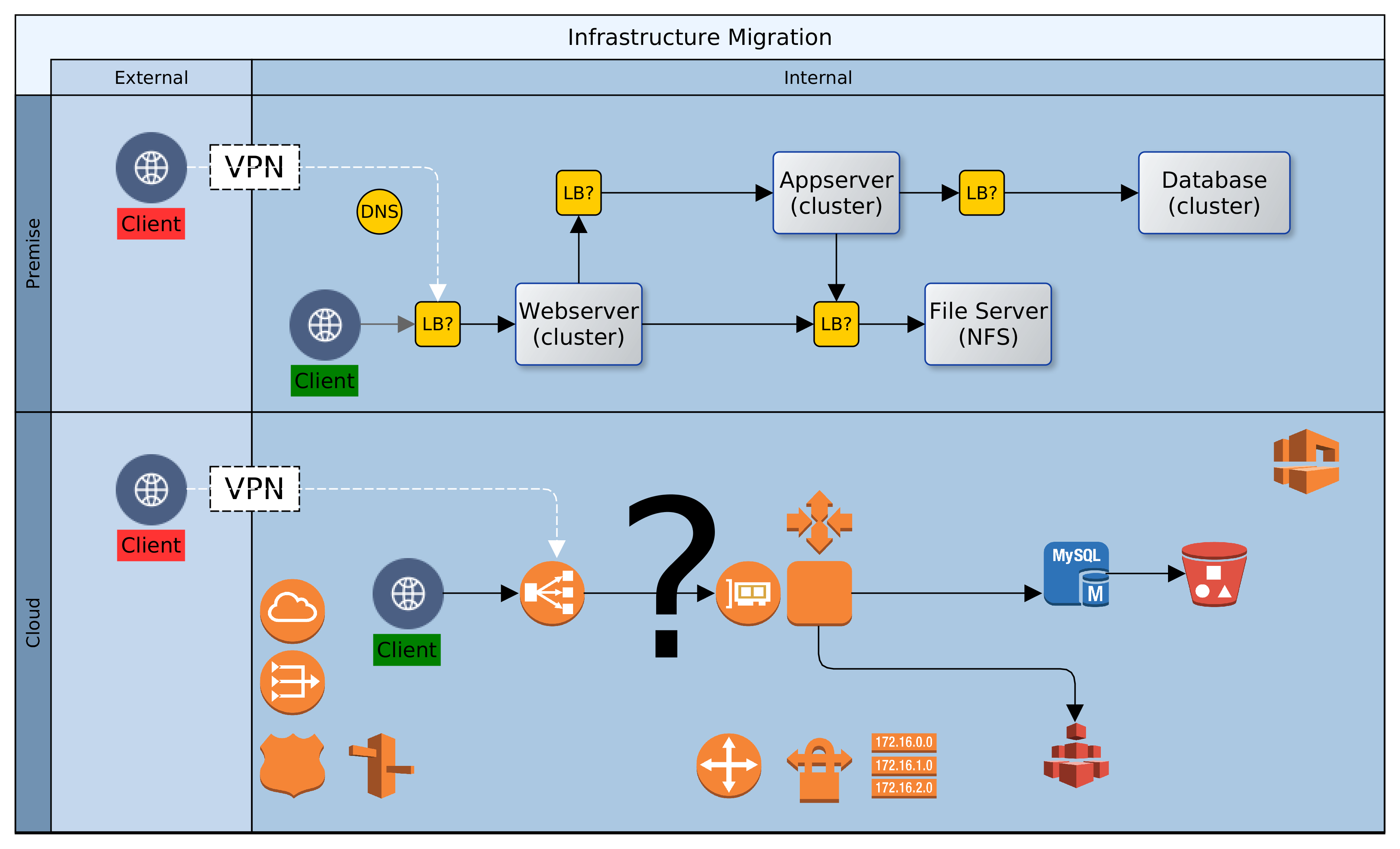
The Cloud may not be in-your-face. But it is pervasive, and gradually taking over many aspects of our traditional IT systems. Companies are not yet making wholesale transitions from existing data-centres and on-premise assets to Cloud. However, when infrastructure reviews occur, whether to upgrade or add new resources, the Cloud beckons. Questions about total cost of ownership (TCO), scalability, time-to-market, etc will influence decision makers. For each one of these, the Cloud offers a compelling alternative. It is likely that in the next two decades, only a few companies will still maintain their infrastructure on premise.
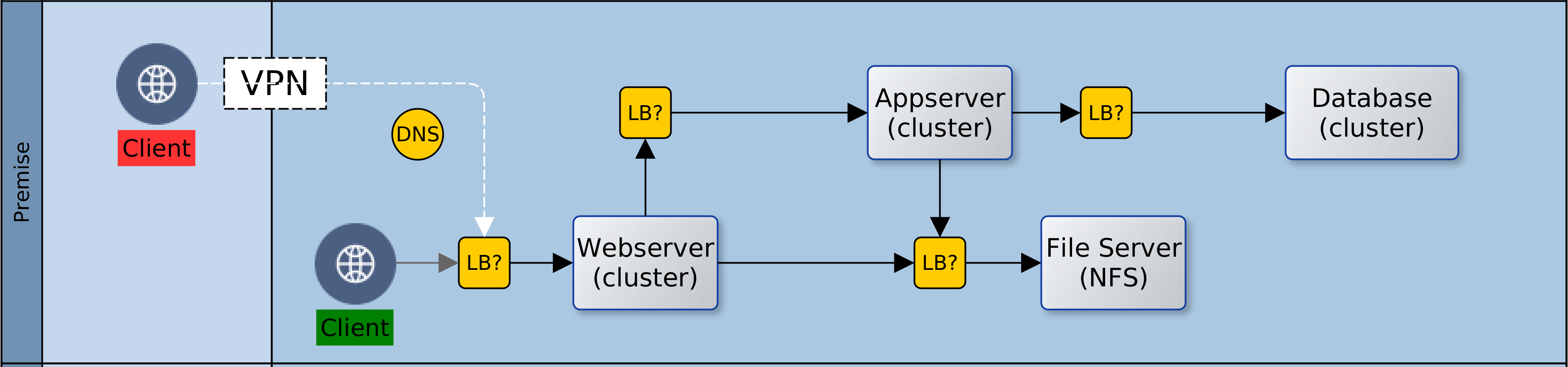
Let us assume then that ACME plc has made a decision. Business has been persuaded, either by hype or fundamentals, that the Cloud is the strategic target. Architectural leadership has been mobilised and a decision taken to draw up a roadmap for Cloud adoption. What next? In this article, we look at four primary considerations that architects must carefully examine when migrating to the Cloud. These are: sizing, failover, scaling and access. Everything else builds on the foundation that is synthesised from these four dimensions.
Sizing: What Specification of Infrastructure Should be Provisioned
Statistics are invaluable. Node sizing should be empathetic to existing use profile. It may be okay to guess at first, but it saves so much time to know in advance. For each Cloud instance, the node(s) provisioned should be selected to meet latency and throughput required to support 120% of anticipated production load. The sizing could be either singular or plural. Singular, as in one node with enough capacity to bear all load; or plural, i.e. a number of nodes that can, between them, satisfy demand. But the baseline should exceed the present need.
Resizing in the Cloud may be quick and easy, but the decision making might not be so. If in doubt, over-provision. It is easy to downsize later, and the organisation avoids the risk of loss of business due to performance or availability problems. Default sizing is simple, i.e. geography localised and singular. But there could be exceptional scenarios where geographic distribution must be combined with plural sizing. More about that later.
Failover: How is System Failure Mitigated
Given proper sizing, as above, the next dimension to consider is failure and recovery. If or when a properly sized machine fails; what happens next? Let’s take the simple approach first and we will revisit this later. There should be a distribution of node(s) across Cloud locations, so that the failure of one node does not result in service unavailability. Service recovery should occur in a different Cloud location. This reduces the likelihood of contagion from the original failure location while maintaining service continuity. An interesting aspect of failure management is implicit resilience, i.e. what measure of interuption can our infrastructure handle?
The complement of the nodes that provide a service across Cloud location(s) is a resource group. The group resilience is the count of simultaneous failures that can be managed while maintaining SLAs. The higher the count, the larger the number of nodes and Cloud locations involved. Resiliency has a price tag though. More machines (virtual) will multiply cost and increase the percentage of idle/redundant resources in the Cloud platform.
Scaling: How are Additional Resources Provisioned
As resource demand grows organically, or due to unexpected spikes, infrastructure should respond, automagically! Traditionally, scaling was a bureaucractic and technical journey. With Cloud, scaling is merely a change of configuration. Where singular sizing has been used, another node of the same size could be added. This is horizontal scaling. Adding more nodes to singular sized nodes would multiply capacity. It is linear, but there is no guarantee of commensurate increase in demand or resource usage. There is an alternative design that is more efficient: programmatic vertical scaling. A simple algorithm can be applied to automatically scale resources; up or down, by a fraction rather than a multiple.
Cloud platforms record a raft of events about the resources deployed. Customers can tap in to these events to scale in response to demand. On AWS, CloudWatch alarms can trigger a Lambda function, which in turn effects a rolling upgrade on EC2 nodes; upscaling node size before autoscaling. By leveraging statistics for baseline sizing and monitoring demand, we can guarantee day zero availability and decent response in infrastructure provisioning. Increasing capacity as demand grows and shrinking it if or when spikes even out.
Access: How do Clients Connect to Cloud Services
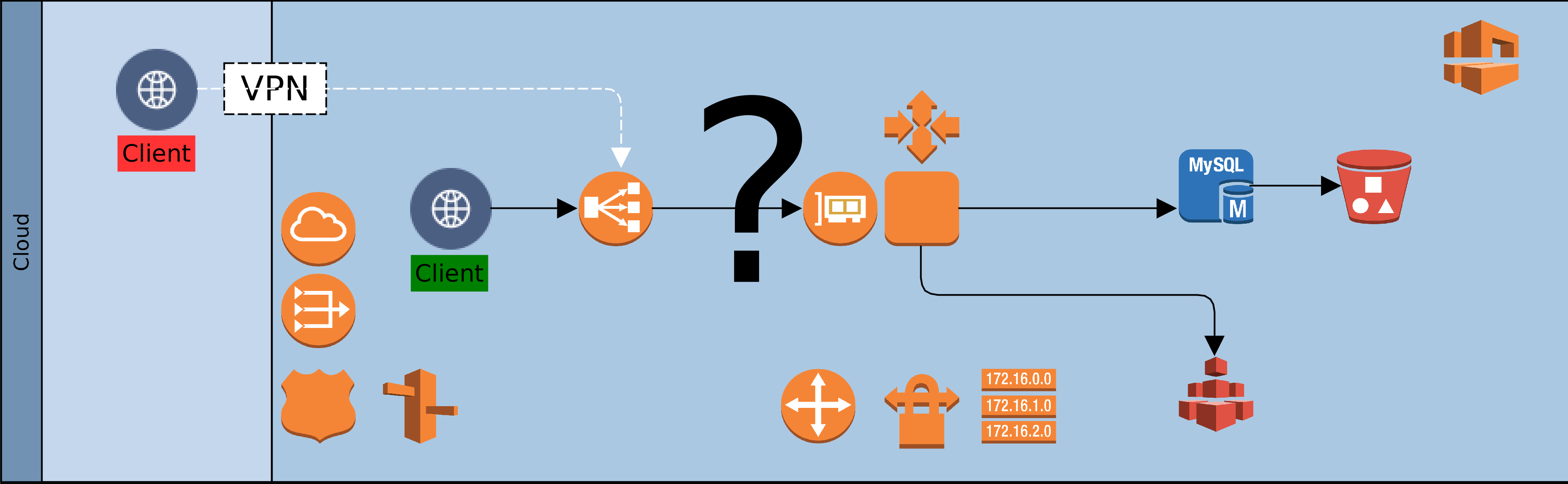
The fourth dimension is access. As on-premise, so also with Cloud. There is no value in having resources that are locked away from everyone and everything. Our clients need access to our Cloud based services, so also partners involved in our service chain. Unless we are migrating all at once, it is likely that we will also need access to some on-premise infrastructure. Our design must provide the access paths and levels, as well as the constraints that keep authorised clients within band and everyone else out. To achieve this we would use such facilities as the Virtual Private Network (VPN), the load balancer, firewalls and others. Beyond the basics of who’s in and who’s out though, there is a service that we must provide to clients and partners.
The key here is to be simple and unobtrusive; placing minimal burdens on clients, partners and our applications/services.
By default we would use load balancers to decouple clients from service providers. Cloud load-balancers spread requests among available service providers. They are not geography specific and simplify access and security for clients and service provider. Our Cloud landscape is elegant and uncomplicated, with singular entry points for each service. One consideration could however force radical change to this default: Geographic Affinity (GA). Geographic affinity is a requirement to pin clients to a specific physical/geographical service provider. It could be zonal or regional. GA is often driven by regulatory, localisation, performance or security concerns.
But some GA drivers can be conflicting. For example, performance (latency sensitive applications) might be a problem where localisation (regional) is required. Invariably, GA tilts our architecture towards plurality of nodes and complications in managing performance and synchronisation of state. Architects must balance, sometimes conflicting, needs to avoid creating virtual silos in the Cloud.
Cloud Chaos
The Availability Index
So far we have been working forwards from an existing status quo to a target architecture. We have also adopted an exclusively technical perspective. What would be better is to take a business perspective. To approach our context top down. We should ask: what infrastructure is needed to support our business vision, now and into the near future? What level of availability is enough to provide service that exceeds client needs. In asking these questions, we encounter a new concept: “the Granularity of Perception”. This can be described as the number of microseconds, milliseconds, seconds, minutes, or more that impacts our service(s), as perceived by clients. Simply put: how slowly can we blink before our clients start to notice that our eyes have moved. As this number (granularity) increases, the required level of availability decreases. The table below provides a rough guide, with descriptions.
Availability Index
Description
1
Cluster enabled, auto recovery, no fail 24×7, latency intolerant, high-frequency, geography affinity
3
Cluster enabled, auto recovery, no fail 24×7, latency intolerant, medium frequency
5
Cluster enabled, auto failover, business hours, latency tolerant, low frequency
7
Non clustered, manual failover, business hours, latency tolerant, low frequency
The goal of architects should be to design a Cloud platform that delivers a granularity that is finer than the perception of clients. Using the table above as a guide, architects should play out scenarios with the service portfolio against each index. Starting with the least to the highest. Once the required availability index is determined, it should be relatively easy to identify the dimensions to support it.
Conclusion
As organisations embark on the journey of digital transformation, one early change is often Cloud adoption. This is because the Cloud provides a catalysing medium in which many solutions are easier and quicker to provision. In moving from on-premise/data-centre resources to the Cloud, architects must resist the temptation to simply lift-and-shift. Rather, the digital transformation journey should re-examine the fitness-for-purpose of existing solutions, platforms and infrastructure. There is a famous quote by Jack Welch, former CEO of General Electric. He said, “If the rate of change on the outside exceeds the rate of change on the inside, then the end is near.”. In a rapidly evolving globalised economy, business agility is becoming a precondition for survival.
The availability index is a simple, logical, technology-agnostic technique for conceptual reasoning about a Cloud landscape. Determination of the availability index helps to reveal shared profiles for similar subsystems. The profiles are logical and help estimate the resources required to support a genre of subsystem. Each logical profile can then be mapped to specific Cloud infrastructure and captured as customisable templates. The logical profiles provide architects with a starting point for solution designs. The infrastructure templates serve as a baseline for DevOps teams. Each artefact is likely to go through a number of evolutions. However, it is vital that both views are kept in sync at all times.
Organisations that leverage this approach will see a marked improvement in the consistency of infrastructure designs. Other benefits include faster turnaround of solutions, and systems that balance technical capability with business needs and aspirations. Architecture teams that leverage the availability index position their organisations for superior agility and competitiveness in the global economy.
In a previous article, “One thousand servers, start with one click”, I described the design and implementation of a simple hybrid-Cloud infrastructure. The view was from a high level, and I intend, God willing, to delve into the detail in a later instalment. Before that though, I wanted to touch on the subject of hybrid Cloud security, briefly.
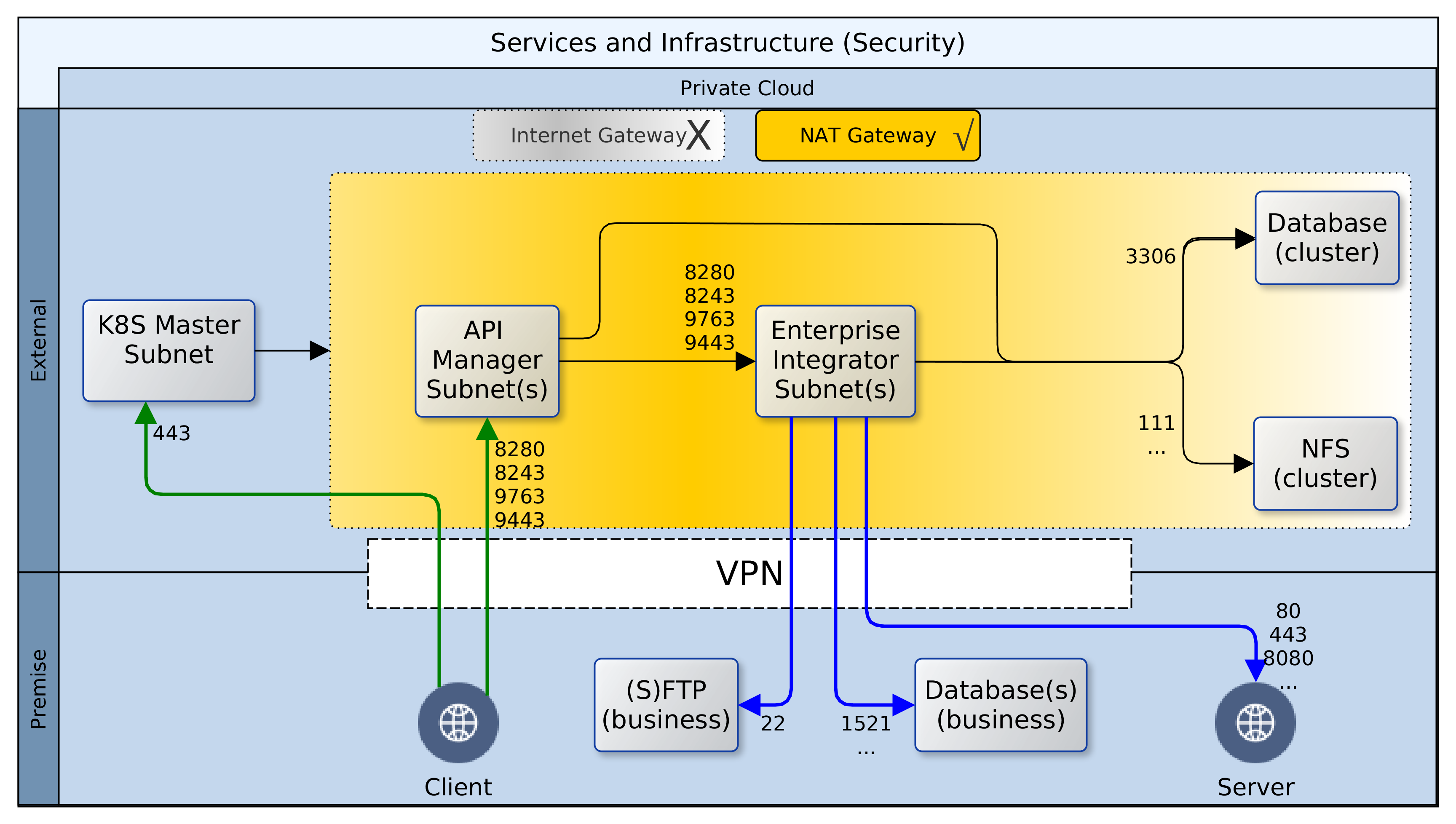
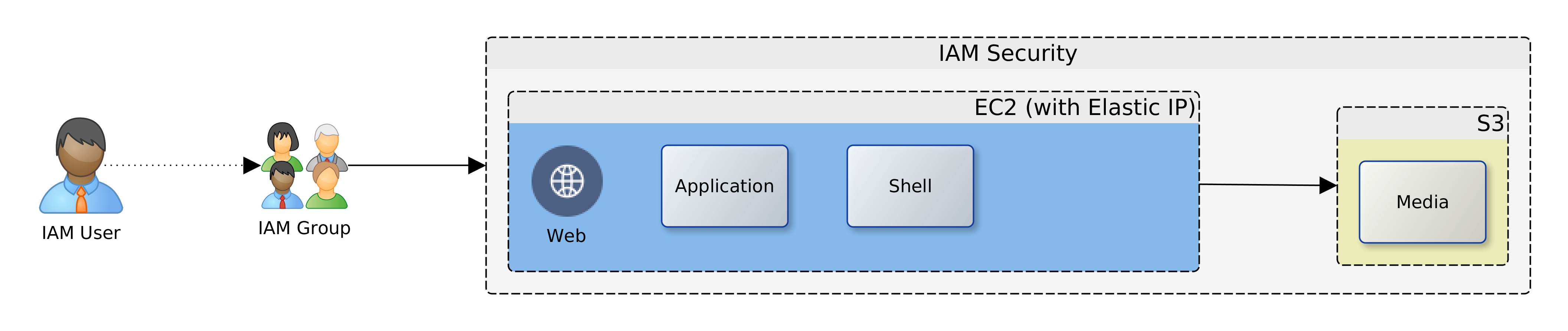
Having deployed resources in a private Cloud and on-premise, certain precautions should be taken to secure the perimeter and the green zone inside the two networks – Cloud and premise. The diagram above paints the big picture. It shows how, based on AWS security recommendations, minimal access/privilege is granted to each resource in the networks. The focus here is on machine access, which is about the lowest level of security. I will not delve into AWS policies, VPN configuration or on-premise firewall rules, as these are not black-and-white and the detail involved does not fit in with the goal for this article.
Here goes! Reading the diagram and translating to words:
It is convenient to use the Internet Gateway (public router) of your Cloud provider during development. Once you are done with prototyping and debugging, it should be disabled or removed. Switch to a NAT gateway (egress only router) instead. Your servers can still connect to the outside world for patches, updates, etc. but you can control what sites are accessible from your firewall. Switching to a NAT gateway also means that opportunist snoopers are kept firmly out.
Open up port 443 for your Kubernetes (K8S) master node(s) and close all others – your cluster can even survive without the master node, so don’t by shy, lock it down. Should the need arise, it is easy to temporarily change Cloud and premise firewall rules to open up port 22 (SSH) or others to investigate or resolve issues. Master nodes in K8S master subnet should have access to all subnets within the cluster, but this does not include known service ports for the servers or databases.
While your ESB/EI will have several reusable/shared artefacts, the only one that are of interest to your clients (partners) are the API and PROXY services. For each one of these services, a Swagger definition should be created and imported into the API Manager (APIM). All clients should gain access to the ESB/EI only through the interfaces defined in the APIM, which can be constrained by security policies and monitored for analytics. Therefore, the known service access ports should be open to clients on the APIM, and as with the K8S master, all other ports should be locked down.
Access to the known service ports on the ESB/EI should be limited to the APIM subnet(s) only, all other ports should be closed.
The Jenkins CI/CD containers are also deployed to the same nodes as the ESB/EI servers, but they fall under different constraints. Ideally, the Jenkins server should be closed off completely to access from clients. It can be correctly configured to automatically run scheduled and ad-hoc jobs without supervision. If this is a challenge, the service access port should be kept open, but only to access from within the VPN, ideally, a jump-box.
Access to the cluster databases should be limited to the APIM and ESB/EI subnets only, and further restricted to known service ports – 3306 or other configured port.
Access to the cluster NFS should be limited to the APIM, ESB/EI, and K8S-master subnets only, and further restricted to known service ports – 111, 1110, 2049, etc., or others as configured.
On-premise firewall rules should be configured to allow access to SFTP, database, application and web-servers from the ESB/EI server using their private IP addresses over the VPN.
Wherever possible, all ingress traffic to the private Cloud should flow through the on-premise firewall and the VPN. One great benefit of this approach is that it limits exposure; there are fewer gateways to defend. There are costs though. Firstly, higher latencies are incurred for circuitous routing via the VPN rather than direct/faster routing through Cloud-provider gateways. Other costs include increased bandwidth usage on the VPN, additional load on DNS servers, maintenance of NAT records, and DNS synchronisation of dynamic changes to nodes within the cluster.
ADDENDUM: Except for SFTP between the ESB/EI server and on-premise SFTP servers, SSH/port-22 access should be disabled. The Cloud infrastructure should be an on-demand, code-driven, pre-packaged environment; created and destroyed as and when needed.
And that’s all folks! Once again, this is not an exhaustive coverage on all the aspects of security required for this hybrid-Cloud. It is rather a quick run-through of the foundational provisions. The aim being to identify a few key provision that can be deployed very quickly and guarantee a good level of protection on day one. All of this builds on a principle adopted from AWS best practise. The principle states that AWS is responsible for the security of the Cloud while end-users are responsible for security in the Cloud. The end-user responsibility of Cloud security begins with another principle: access by least privileges. This means that for a given task, the minimum privileges should be granted to the most restricted community to which one or more parties (man or machine) is granted membership.
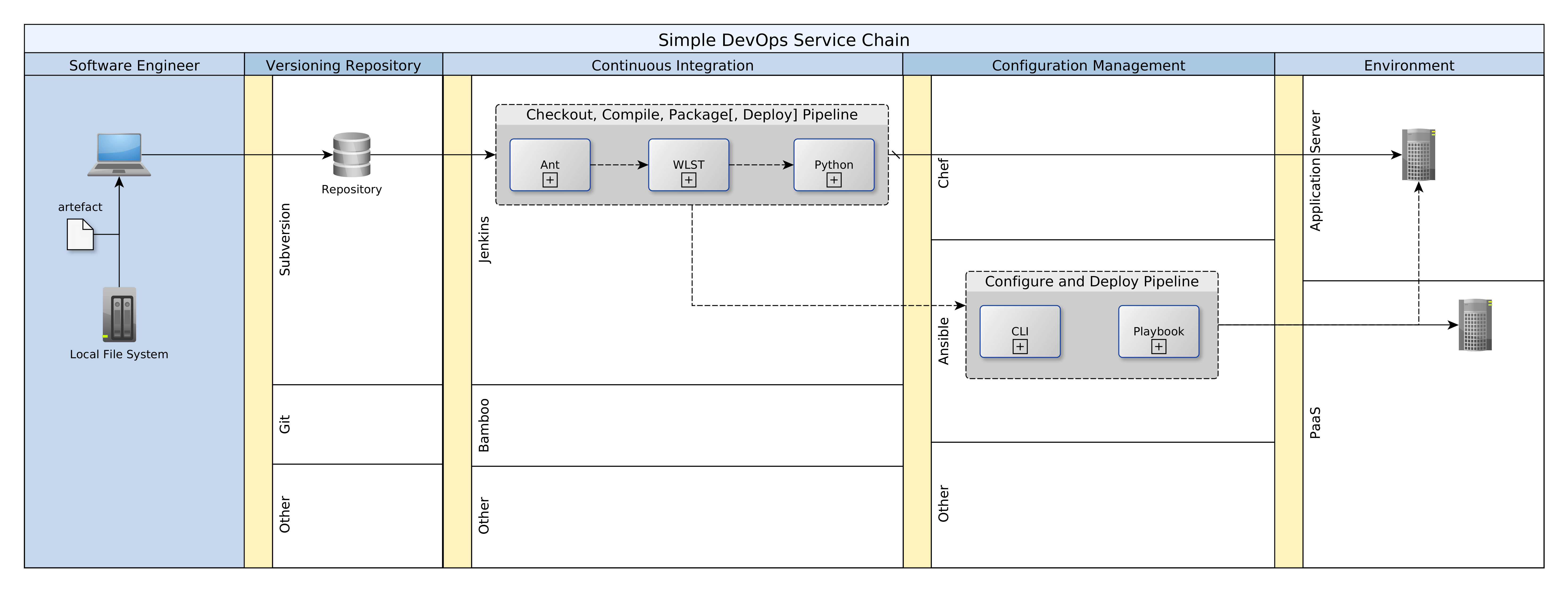
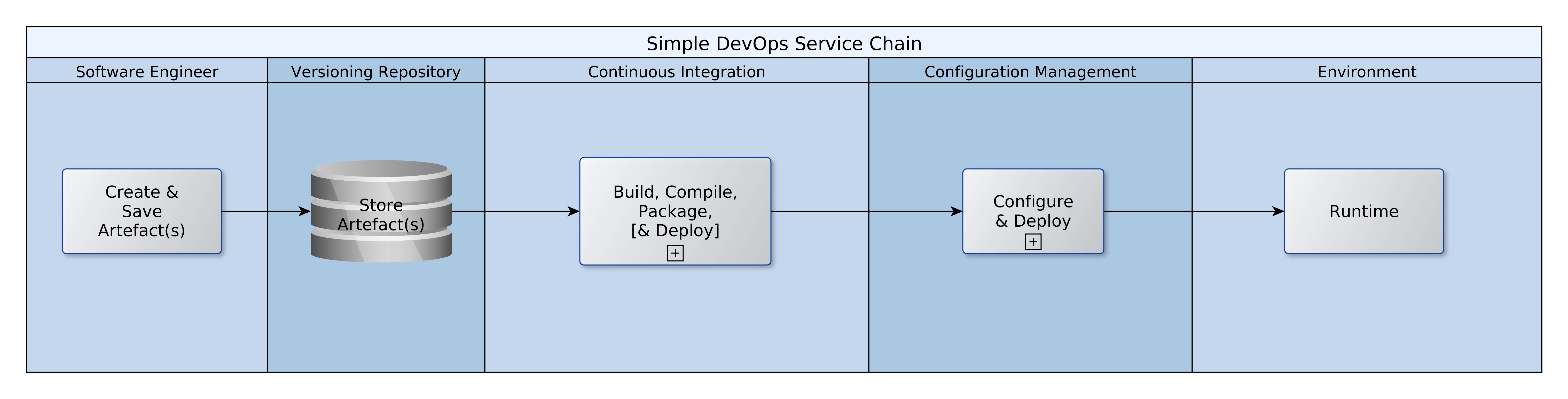
A Pipeline of Tasks Illustrating a Simple DevOps Chain
DevOps is the amalgalm of development activities and the business continuity provided by operations teams. It unites the efforts of what are still two teams, with different competencies, into one value chain. DevOps creates and sustains a unified process for transforming technical requirements into live code in production systems. In this article I walk through a very simple example to illustrate the key concepts and actors involved in the value chain, and how they are linked. The diagram that follows (below) provides a quick high-level view. This article is an adaptation for Jenkins based on a similar post for Maven. Many examples for DevOps are based on Maven. If you have little Maven experience or find yourself in an environment where Ant is already in use, this article will help you get a simple DevOps started quickly.
In the sections that follow, I will be talking about each of the pools of activity in the diagram above.
Creating and Saving Artefacts
The first step of course is to create the artefacts that will power our target systems, whether DEV, TEST, UAT, or PROD. Software engineers are the primary actors in this scope. The term, software engineer, is used here to include developers, testers, DBAs and operations personnel. The term, resources, refers to any code, script, list, sheet, etc. that will either implement, support, or validate our target systems. Software engineers will create resources on their local machines and by saving them to a repository, trigger a chain of events that will take some of those resources into production systems.
There are quite a few repositories available, including Subversion, Git, etc. In this example I have used Subversion, but the process of create, save, commit/update is pretty much the same. The repository is at the heart of everything. We have a rule: an artefact does not exist, unless it is saved and maintained in the repository. Continuous integration and deployment are driven exclusively be resources in the repository.
Continuous Integration (CI)
As with the repository, there are many options; I used Jenkins. Jenkins is used to periodically validate the status quo (code base). It does this by a sequential process, executed on a schedule:
Check out all updated artefacts
Compile and/or validate the artefacts
Package the compiled artefacts
The schedules for each of these steps differ, but there is a dependency from 3 to 2 and from 2 to 1. If step 1 fails, the others are aborted, and if step 2 fails, step 3 is aborted. The checkout is run every 15 minutes, the compile is run hourly and the package is run every other hour. Each of these three steps are executed for the artefact groups used: MDS, OSB, BPEL. If any of the jobs fail, the Jenkins administrator is notified by email with details about the job and optionally the log output.
Apart from the integration with Subversion via a plugin, the Jenkins service relies heavily on an Ant build file for running each of these jobs. The flow of data/control for each job is as follows:
Jenkins job is started (manually or on schedule)
Jenkins invokes Shell script
Shell script invokes Ant
Ant executes a task/target
Three separate Ant build files for each of the artefact groups: MDS, OSB, BPEL. This is for ease of maintenance, and because the names of the targets/tasks are the same: compile, clean, package, etc. However, all the build files share the same property file since many of the properties are common to all builds.
Configuration Management
Once the artefacts have been packaged, they are ready for deployment. Once again, there are a number of options. We could use Chef, Ansible, Jenkins, Puppet, Bamboo, etc.. Now, if you have to build the machine before you can deploy you are left with no choice but to use proper CD tools like Ansible, Chef, or Puppet. In this case the platform was already available and so I used Jenkins and Ant once again. A Jenkins job was created for deploying to target environments. The deploy job should be scheduled for DEV (every morning) but manual for all other environments. In addition, there should be offline governance controls over the manual deployment to non-DEV environments.
Smoke Testing
Once the artefacts are successfully deployed to the target environment, it is useful to test the services. There are quite a few options available for testing deployed services, including JMeter, SOAP-UI, etc. The testing could be carried out manually, managed offline, or integrated with Jenkins.
The automation of these essential tasks help to free developers from the bother of checking systems and code for breakages. Instead, the Jenkins services continuously build and check the source code to ensure that the baseline is stable.
Amazon Web Services (AWS) have revolutionised the way we view IT provisioning. AWS makes so many things easier, and often cheaper too. The benefits scale from the SME right up to corporates; no segment is left out. Complexity is abstracted away, and with a little effort, large and/or complex systems can be built with a few clicks and some configuration.
Architecture
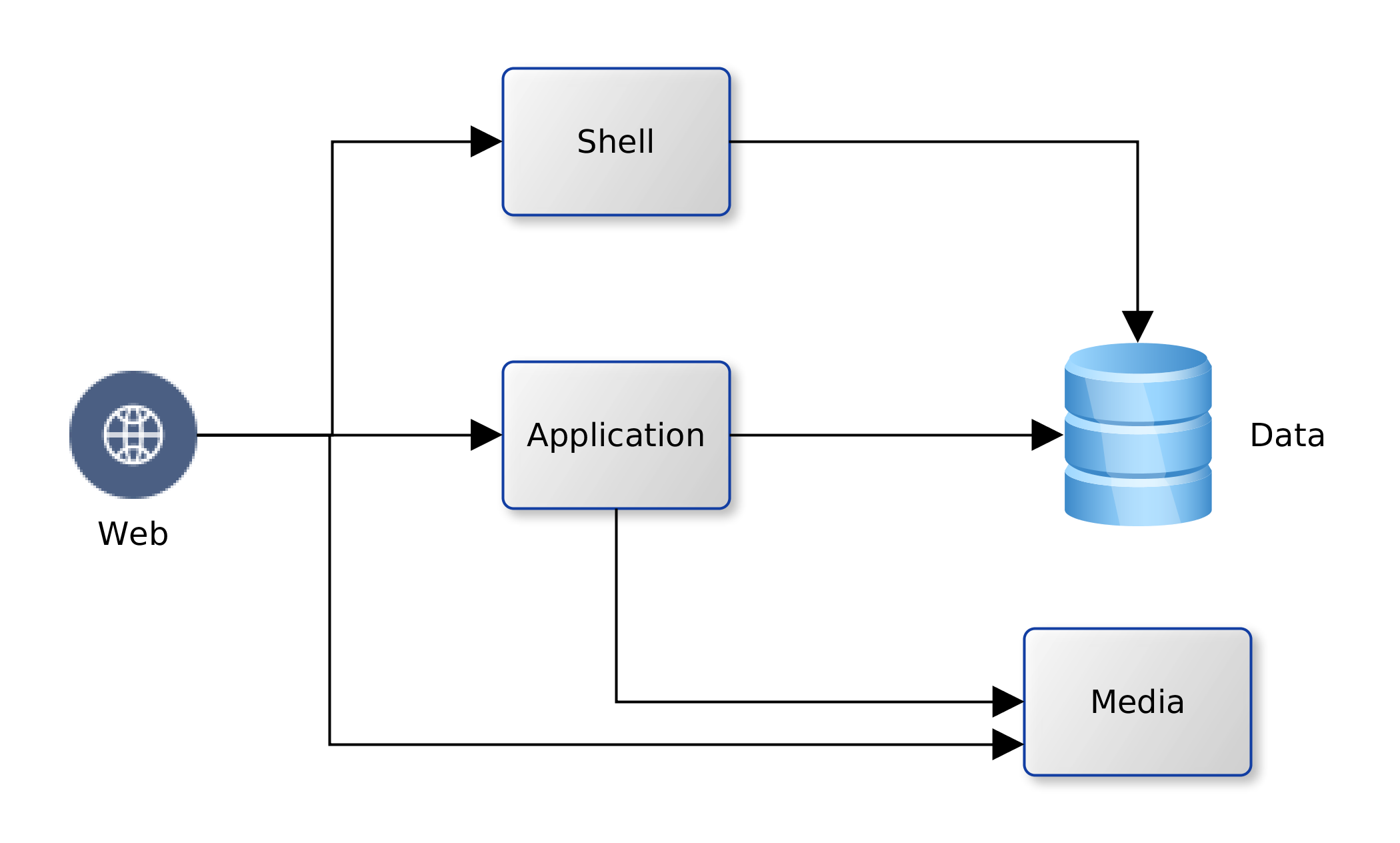
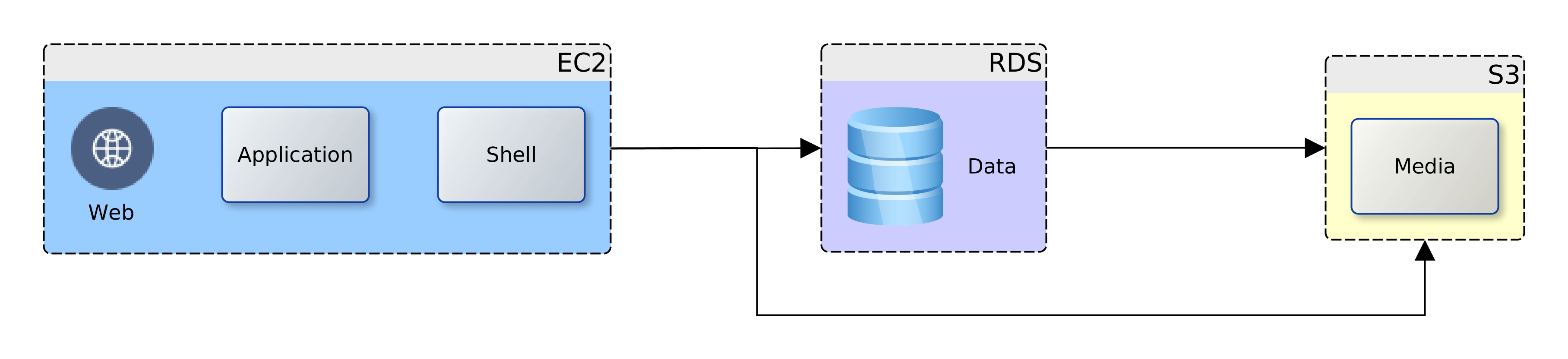
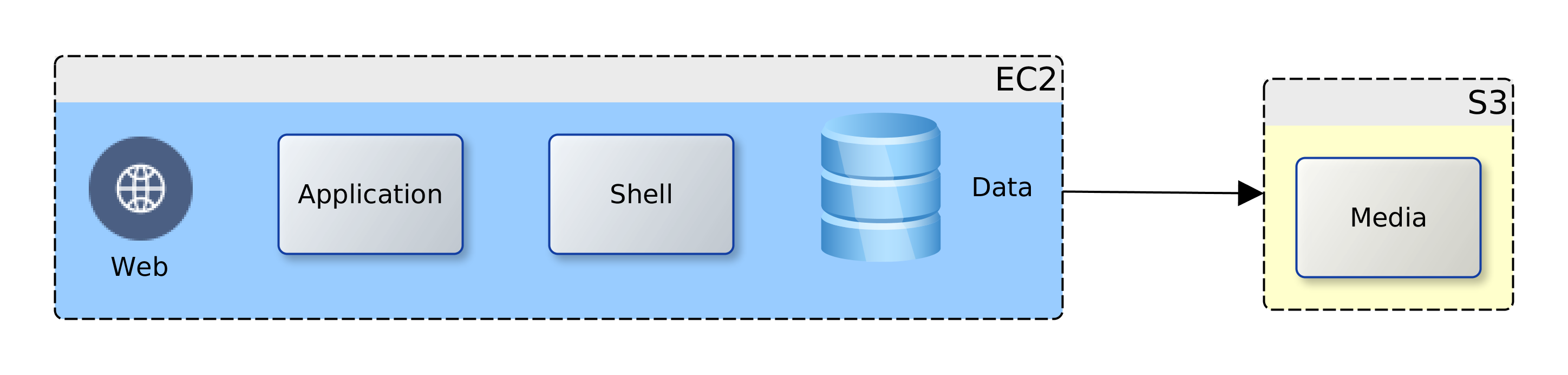
We decided to take a quick look and see just how much the AWS could offer low-budget SMEs. Using our company’s existing platform as the subject. We have one Oracle database and a handful of MySQL databases; an application server and a Web Server fronting for the application server and several CMS-driven sites. The application server runs Java web services that use data from the Oracle database. The web server hosts the pages for the Java application. It also servers a number of WordPress/PHP sites that run on data from the MySQL databases. The logical view is illustrated in the diagram below: We could map the logical view to one-to-one service units in AWS, or rationalise the target resources used. AWS provides services for computation for web and application (EC2) Shell scripting (OpsWorks), data (RDS) and static web and media (S3), and other useful features; Elastic IP, Lambda, IAM. So, we have the option to map each of the logical components to an individual AWS service. This would give us the most flexible deployment and unrivalled NFR guarantees of security, availability and recoverability. However, there would be a cost impact, increased complexity, and there could be issues with performance.
Solutions
Going back to our business case and project drivers; cost reduction is highlighted. After some consideration two deployment options were produced (below), and we therefore chose the consolidated view. The Web, application and data components were targeted at the EC2 instance as they all require computation facilities. All the media files were targeted at the S3 bucket. The database data files could have been located on the S3 bucket but for the issue of latency, and costs that would accumulate from repeated access.
The media files were targeted to the S3 bucket due to their number/size (several Gbs). The separation ensures that the choice of EC2 instance is not unduly influenced by storage requirements. The consolidated view allows us to taste-and-see; starting small and simple. Over time we will monitor, review and if need be, scale-up or scale-out to address any observed weaknesses.
Migration
Having decided on the target option, the next thing was to plan the migration from the existing production system. An outline of the plan follows:
Copy resources (web, application, data, media) from production to a local machine – AWS staging machine
Create the target AWS components – EC2 and S3, as well as an Elastic IP and the appropriate IAM users and security policies
Transfer the media files to the S3 bucket
Initialise the EC2 instance and update it with necessary software
Transfer the web, application and data resources to the EC2 instance
Switch DNS records to point at the new platform
Evaluate the service in comparison to the old platform
Implementation
The time arrived to actualise the migration plan. A scripted approach was chosen as this allows us to verify and validate each step in detail before actual execution. Automation also provided a fast route to the status quo ante, should things go wrong. Once again we had the luxury of a number of options:
Linux tools
Ansible
AWS script (Chef, bash, etc.)
Given the knowledge that we had in-house and the versatility of the operating system (OS) of the staging machine, Linux was chosen. Using a combination of AWS command line interface (CLI) tools for Linux, shell scripts, and the in-built ssh and scp tools the detailed migration plan was to be automated. Further elaboration of the migration plan into an executable schedule produced the following outline:
Update S3 Bucket
Copy all web resources (/var/www) from the staging machine to the S3 bucket
Configure EC2 Instance
Install necessary services: apt update, Apache, Tomcat, PHP, MySQL
Add JK module to Apache, having replicated required JK configuration files from staging machine
Enable SSL for Apache … having replicated required SSL certificate files
Fix an incorrect default value in Apache’s ssl.conf
Configure group for ownership of web server files www
Configure file permissions in /var/www
replicate MySQL dump file from staging machine
Recreate MySQL databases, users, tables, etc.
Restart services: MySQL, Tomcat, Apache
Test PHP then remove the test script …/phpinfo.php
Install the S3 mount tool
Configure the S3 mount point
Change owner, permissions on the S3 mounted directories and files – for Apache access
Replicate application WAR file from staging machine
Restart services: MySQL, Tomcat, Apache
Finalise Cutover
Update DNS records at the DNS registrar and flush caches
A few observations are worthy of note, regarding the use of S3. AWS needs to make money on storage. It should therefore not be surprising that updates to permissions/ownership, in addition to the expected read/write/update/delete, count towards usage. Access to the S3 mount point from the EC2 instance can be quite slow. But there is a workaround: use aggressive caching in the web and application servers. Caching also helps to reduce the ongoing costs of repeated reads to S3 since the cached files will be hosted on the EC2 instance. Depending on the time of day, uploads to S3 can be fast or very slow.
Change Management
The cut-over to the new AWS platform was smooth. The web and application server resources were immediately accessible with very good performance for the application server resources. Performance for the web sites with resources on S3 was average. Planning and preparation took about two days. The implementation of the scripts for migration automation took less than 30 minutes to complete. This excludes the time taken to upload files to the S3 bucket and update their ownership and permissions. Also excluded is the time taken to manually update the DNS records and flush local caches.
Overall, this has been a very successful project and it lends great confidence to further adoption of more solutions from the AWS platform.
The key project driver, cost-saving, was realised, with savings of about 50% in comparison with the existing dedicated hosting platform. Total cost of ownership (TCO) improves comparatively as time progresses. The greatest savings are in the S3 layer, and this might also improve with migration to RDS and Lightsail.
In the next instalment, we will be looking to extend our use of AWS from the present IaaS to PaaS. In particular, comparison of the provisioning and usability of AWS and Oracle cloud for database PaaS. Have a look here in the next couple of weeks for my update on that investigation.
There are quite a few new features in Oracle BPEL 12c and here is one that I really like; the BPEL subprocess – a task/algorithm that is an association (not composition) of an activity/process.
The concept has been around for decades and it has featured in process diagrams and BPMN notation for quite a while, but there was no equivalent in program code. Oracle has finally addressed this lacuna by releasing a feature in BPEL that closely approximates the design concept. Please note that it is close but not identical in semantics; but that again is to be pedantic – pardon the pun!
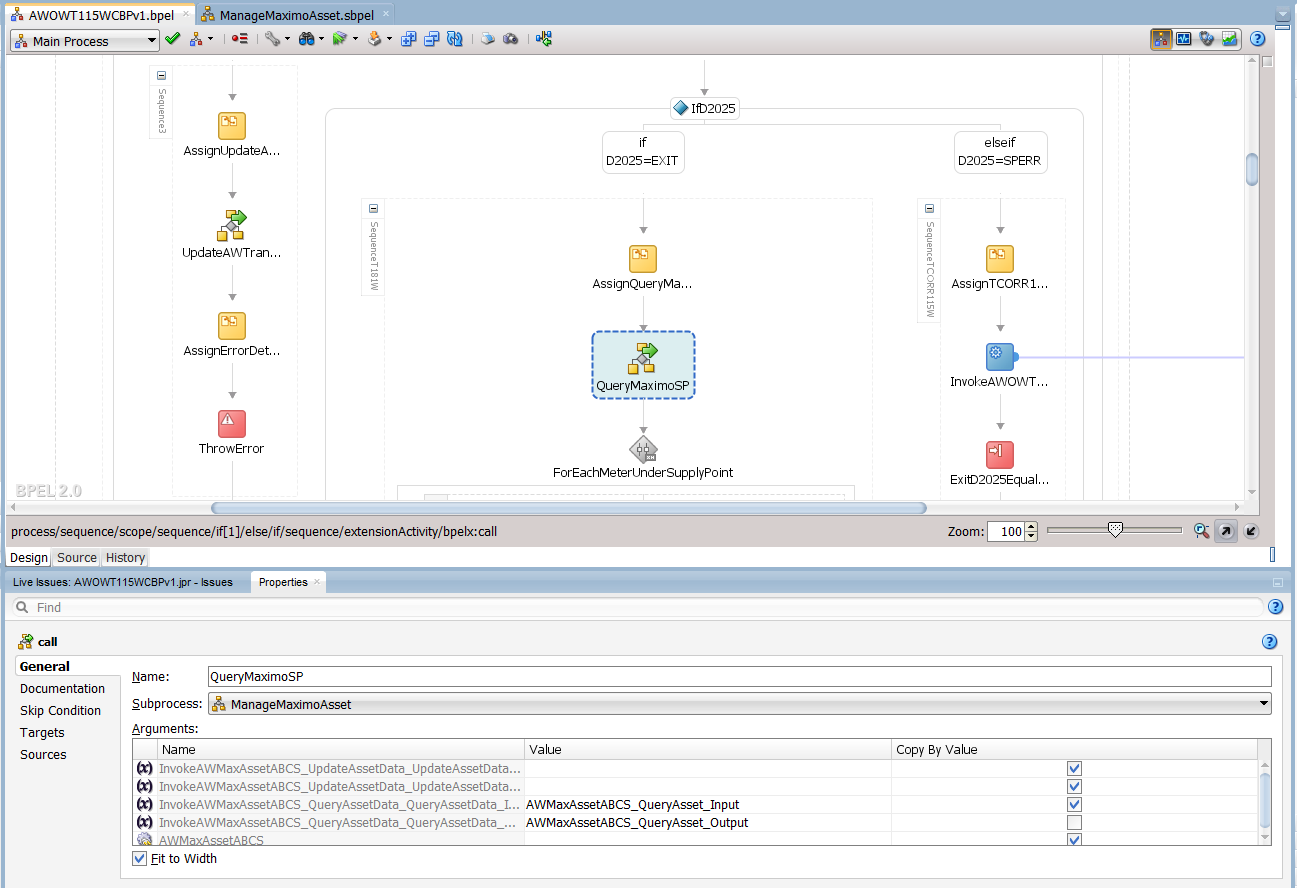
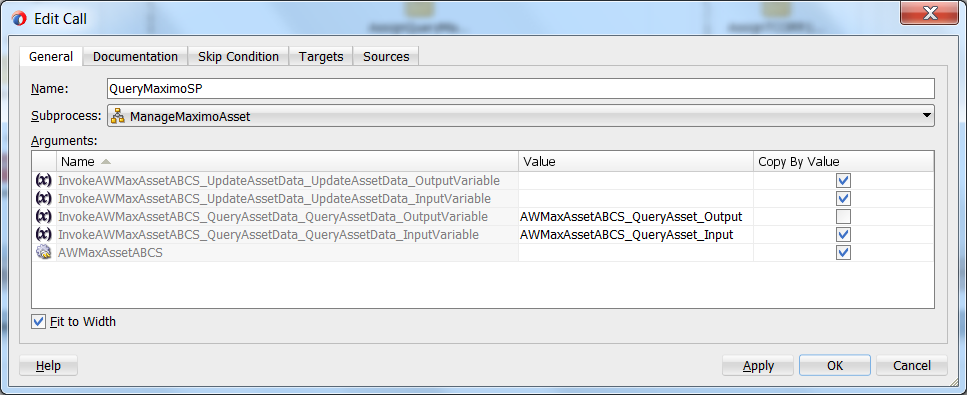
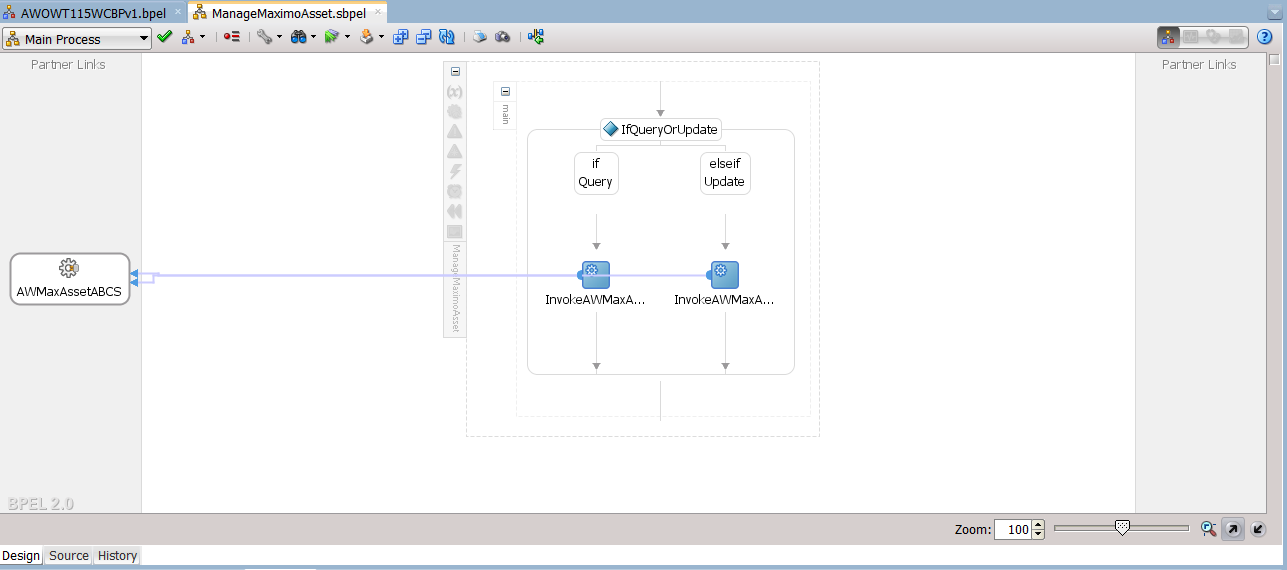
The subprocess allows a programmer to define a block of code or algorithm that will be reused as-is at various points within one or more BPEL processes. I took the liberty of taking a few screenshots of active code from a recent client in order to illustrate a subprocess in action. Before diving in though, it is useful to set the context. The subprocess is being used in this scenario to wrap the invocation of operations on a service, and the task is named here as “QueryMaximoSP” – see highlighted item in the diagram below.
Call to the subprocess from the parent process
This subprocess wraps all the operations on the AWMaxAssetABCS service, and can determine which one is to be invoked by examining the inputs it receives from a main process. In this simple example, the choice is implemented as if/else paths for “query” and “update” operations. Once the operation has been determined invocation of the target service follows, using the input that was passed in by the main process.
Subprocess internal details
There are three benefits that this concept brings to BPEL code:
Simplification of design view
Improved reusability
Improved modularisation
In the design view, hiving off some code into a subprocess frees up the screen from clutter and makes it much easier to see the big picture of what we are doing in the main process. But what becomes of all this delegated code in production systems? One fear may be that the subprocess will be displayed as a black-box. This is not the case, all steps in the subprocess will be revealed at runtime, but only if they are executed.
Modularisation is improved because programmers can delegate as much logic to the subprocess as needed, including specialised error-handling and rollback, pre/post processing, and other conditional processing. All of this functionality is thereafter available to all processes within a SOA composite, and each can invoke (reuse) the same subprocess multiple times with different inputs.
In the diagram below, input has been provided for the query operation while the update operation has been left blank, and so only the query operation will be acted upon in the subprocess. Notice also that the “Copy By Value” checkbox of the output variable has been left unchecked. This is important, as the invocation is likely to fail on the output variable if the checkbox is checked.
I have found it really useful to encapsulate the invocations to partner services in subprocesses, so that I can control all necessary pre and post processing in one place, as well as any necessary error handling and recovery that is specific to that partner system. In future, it would be nice to have subprocesses that more closely resemble the concept in process models, i.e. a unit of functionality that can be reused across the domain, not just within one composite. Now, some would argue that we should create a new composite to encapsulate the required functionality, but of course that would not be the same thing as in the model, and such a construct would also be significantly slower, not to mention that it would not fit nicely into a service portfolio. Let’s wait and see if Oracle will be tweaking this feature in the next release of the JDeveloper and SOA Suite; for now though, there are already some great benefits realised in subprocesses. I hope you find it useful too.
Rhema Bytes: A Factory Approach to Service Engineering
Service factory abstraction
When most people think of a factory, the imagery that is conjured is one of mindless repetition, and the generation of large numbers of low-value items. A good example is a nut & bolt factory. In this world, value accrues to the investors from the little profit made on each one of the millions, or billions, of items.
This does not tell the full story of factories. There is another view that most of us do not readily think of. I call this genre, a compositing factory. Good examples are found in the many custom bike shops found across the USA. Many of who arrange engines from Harley Davidson, and kit from other suppliers, into dream-machines especially tailored for their high-end clients.
Both perspectives have one thing in common. In real life, there are the designers that articulate a general template of the “thing”. And there will be the producers that directly replicate the template, or customise it before replication. The nut & bolt represents the former (direct-replication), while the custom bike shop illustrates the latter (customised-replication). There are templates and meta-templates for both bike and nut. The nut template will be driven by permutations on materials, size and strength, whereas the bike template is a composition of an engine, frame, gears, tyres and some other bits.
In SOA architecture and design, we are also concerned with templates (ABB and SBB in TOGAF). Our templates are sometimes abstract, sometimes concrete, sometimes composite, sometimes atomic. Whether as a reference architecture, or a component design, the focus is on a template that solves a generic problem. However, most of the time, these templates are not to be replicated verbatim. Their value is almost always realised in some composition or aggregative context. Some intelligence in application being sine qua non.
For any enterprise, there will be a minimal set of services that must be realised for the organisation to be a meaningful participant in its sector. In addition to these core services, there are others that help to differentiate the organisation. These can be regarded as the macro templates. At the micro level, we find that each genre of service must complete certain tasks in order to deliver meaningful value to clients. Once again there could be differentiation by way of order, algorithm or complement, but by and by there will be a minimal set of tasks, that all must do.
If we apply the mindset of the custom bike shop to our architecture practise, we should see quite a few tools in-house that we can use/reuse. Some that can be bought, and a few that we need to fabricate. I have found that while many enterprises adopt the “reuse-buy-build, respectively” principle, not all evaluate the comparative costs of these options before making a decision. The consequence is that build, and buy, usually outnumber reuse in most organisations. In the cases where there is reuse, existing services are rendered functionally ambiguous to cater for slightly different use cases.
In a previous article, “Rhema Bytes: The Business to SOA Nexus”, it was argued that architecture should seek to create a platform of agnostic services that are well suited to serving the genre of an organisation, rather than the organisation specifically. If one were to decompose an enterprise, top-down, it should be somewhat easier to identify functionality at its most granular level. Top-down decomposition helps identify functionality at the highest level of abstraction. The analysis of each granular functional unit can help determine the comparative value of reusing, building or buying services that provide the required competence.
So, for a new business initiative that delivers services X, Y. and Z. We could ask if there is a Harley Davidson engine that fulfills that X, a Volvo axle (Y1), Saab transmission (Y2), and Toyota electrics (Y3) that deliver Y, and if a component Z5a is truly unique, or needs to be built, alongside Z1..Z3, and Z4c that do not already exist in our catalogue.
Each service, whether bought, built, or reused, is then properly catalogued as to the value it provides, its comparative costing, and what contexts it is to be used in. Such a compendium, built over time, makes it much easier to assemble solutions. Every installment of this approach makes the next assembly simpler and quicker. This is because most unique use cases/scenarios are covered off in the early solutions, and subsequent projects will reveal fewer unseen scenarios.
A lasting benefit of this mindset is that federation and outsourcing is made that much easier, since the templates for the product/service or its composition are predetermined. This means that production and assembly can be separated, and the build and testing are more effectively decoupled. In a previous article, “Rhema Bytes: SOA Services Abstraction” one such model for templating service genres in a SOA is explored. Combining this mindset with the pieces identified in that article should result in a flexible, nimble and responsive “service factory”.